By Noxxxx from https://www.noxxxx.com/?post_type=post&p=1488
欢迎分享与聚合,尊重版权,可以联系授权
场景: 用户配音和 CV 配音进行合成,形成一个对手戏的音频对话场景。
AudioContext 是什么?
AudioContext 属于 Web Audio 中的一个 API,创建音频你可以使用
const audio = new Audio();也可以使用 audio 标签,同样可以使用:
const audio = new AudioContext();适用场景
- 音频可视化
- 音频剪辑处理
兼容性
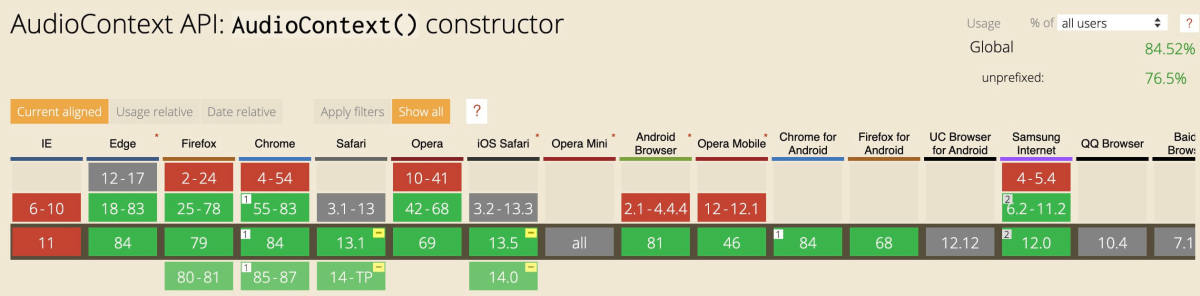
移动端兼容性不错,PC端使用时加上私有前缀。
window.AudioContext =
window.AudioContext ||
window.webkitAudioContext ||
window.mozAudioContextdecodeAudioData 使用回调函数的方式,Safari 不支持 promise 形式的调用。
audioContext.decodeAudioData(arraybuffer, (buffer) => {
resolve(buffer)
})运行流程
AudioContext Api 很丰富但上手略有成本,不过了解基本流程后思路还是比较清晰的。

下面这段代码就可以用来播放音频:
const context = new AudioContext();
var source = context.createBufferSource()
context.decodeAudioData(arrayBuffer, (audioBuffer) => {
source.buffer = audioBuffer
var gain = context.createGain()
gain.gain.value = 0.6
source.connect(gain)
source.start(0)
gain.connect(context.destination)
})首先需要一个音频源,在这里我们使用 audioBuffer通过 Ajax或者 Fetch拿到 ArrayBuffer,然后 decodeAudioDataaudioBufferdestination,默认就是扬声器。所有涉及到播放的都是这么个流程。
这里有一个 demo 更加直观的展示如何连接音频节点进行播放。
演示连接:http://webaudioplayground.appspot.com/
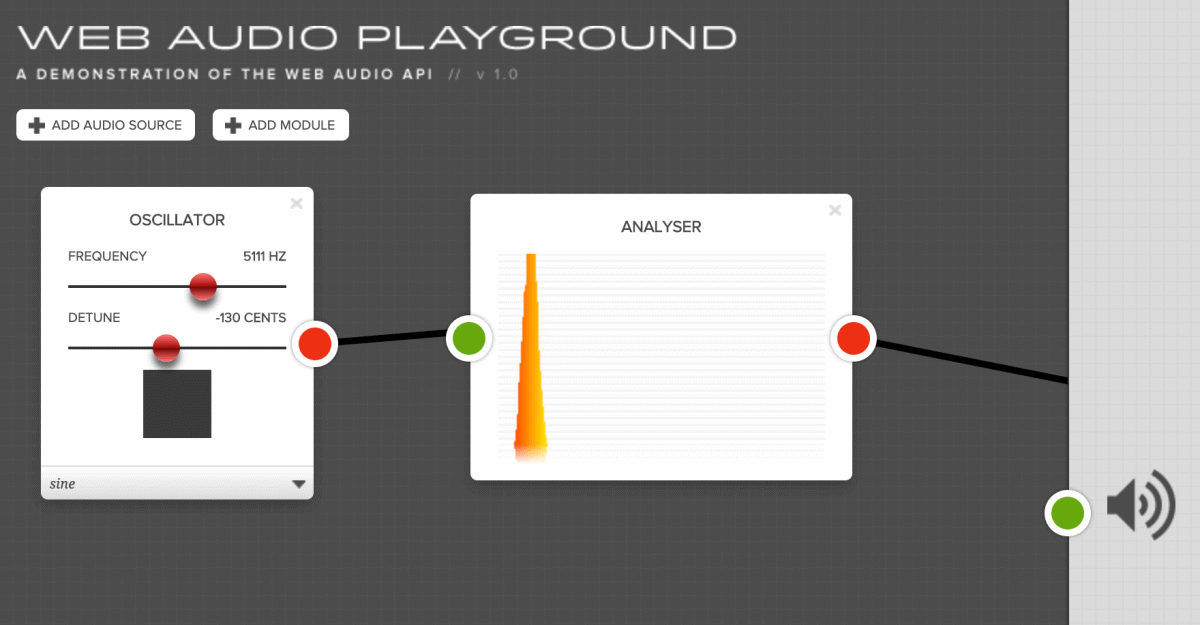
虽然相比 audio API 或者 audio 标签来说略繁琐,但抛开最基础的例子,如果想要对音频数据进行处理,那么标签或者 audioAPI 都没有这个能力。
音频合成
合成有拼接和混合,这里讨论的是拼接,根据文章开头的场景,我们需要把用户和其他人的配音连接到一起,形成一个对话的过程。
下图是合成的一个示意:
我们需要考虑通道(横线代表着上下两个声道,此处认为是立体声)、获取整体长度+设置采样率、选取对应通道的数据进行拼接,最终得到一个拼接后的音频数据,再对这个原始的音频数据添加文件头保存为实际文件(可下载)。

合成代码如下:
const context = new AudioContext();
const buffer = context.decodeAudioData(arrayBuffer);
function mergeAudio(buffers) {
let output = context.createBuffer(
1, // numberOfChannels
totalLength(buffers),
sampleRate
);
let offset = 0;
buffers.map(buffer => {
output.getChannelData(0).set(buffer.getChannelData(0), offset);
offset += buffer.length;
});
return output;
}通常很少人会提到decodeAudioData 其实做了一个重采样的操作,大部分文章都没有提到,而且这个采样率是浏览器取了系统扬声器🔈的采样率,Github Issue 上已经有人质疑这个重采样的操作意义不大且存在性能开销。
在 Mac 中,通过设置扬声器采样率,AudioContext 的 sampleRate 也会随之发生变化。
可以在 Audio MIDI Setup 中调节采样率,测试后发现 iMac 是固定的采样率,MacBook Pro 是可以调节的。
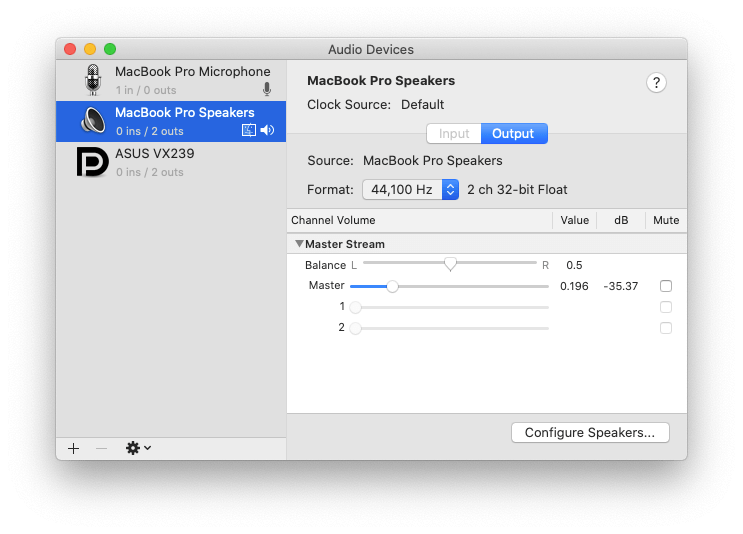
刚开始以为是decodeAudioData 重采样和原始音频文件的采样率不同导致了合成后的声音发生了变化。
原始声音:
合成声音:
如果你不是“木耳”的话,基本上可以听出,合成处理后的音频,音调变了,略中性的感觉,Σ(⊙▽⊙”a。
经过反复的调试之后,发现手机上的采样率是 48 KHZ,而非 44.1 KHZ,通常我们认为 44.1 KHZ 是 CD 播放的品质,48 KHZ 通常使用在“更专业”的录音设备上。
因为采样率越大,录音的文件大小也越大,44.1 KHZ 的音质能满足人耳听觉需求,同时音频质量有保障,文件大小也能保持较小的水平,可谓是一举多得。
那为什么不是其他的采样率呢?不是 40 KHZ,也不是30 KHZ 这种?这里有一个定理叫做: Nyquist-Shannon 采样定理,感兴趣的不妨看一下,各种采样率在基于这个定理上也需要考虑性价比,电话的采样率只有 8000 HZ,如果电话的采样率给一个 蓝光音频的质量,有这个必要么?普遍情况下:电话是用来传播信息,而不是让你花时间来享受信息的音质的(杠精别杠)。
| 采样率 | 用途 |
| 8,000 | 电话、对讲机、满足语音需求 |
| 44,100 | 音频CD |
| 48,000 | 专业音频设备 |
| 96,000 | DVD、蓝光音频 |
当采用 48KHZ 后,合成的声音效果和原始的差不多,没有出现“变声”的情况。
const context = new AudioContext();
const buffer = context.decodeAudioData(arrayBuffer);
function mergeAudio(buffers) {
let output = context.createBuffer(
1, // numberOfChannels
totalLength(buffers),
sampleRate // 此处的采样率设置为 48000
);
let offset = 0;
buffers.map(buffer => {
output.getChannelData(0).set(buffer.getChannelData(0), offset);
offset += buffer.length;
});
return output;
}深入采样率
通常我们对于采样率的认知是: 48 kHz 代表每秒采集 48,000 个点,这是没有问题的,那为什么代码中采样率不同导致了声音出现了变化呢?虽然上述一顿操作解决了声音“变调”的情况,但实际是怎么回事呢?
经过一段时间的查找资料,又发现了一个坑点。
先看这段代码:
var context = new AudioContext();
var buffer = context.createBuffer(1 单声道, 一个长度(代表片段中采样帧的数目),一个采样率(是每秒钟采样帧的个数));先前说过,要合成,就需要先创建一段预设长度的空白 buffer 用来填充数据。
这行代码在实际运行中还是会结合系统扬声器🔈的采样率也进行“重采样”,这在 MDN 上面有说明。
当它在一个频率为44100赫兹的音频环境中播放的时候,将会被自动按照44100赫兹*重采样*(因此也会转化为44100赫兹的片段),并持续1秒:44100帧 / 44100赫兹 = 1秒。
按照 MDN 的说法:我原先设置了 1 个长度的音频,对应 1 个采样率,也就是持续 1s,由于实际环境采样率变成了 2,原始长度扩充到 2,虽然同样是 1s ,但是实际音频内容并没有那么多,那么就会失真。反之属于欠采,低采样率重采样本音频造成数据量减少。
低采样率重采 & 高采样率封装
现象:
- 播放效果类似变声
- 时间变少
- 文件大小变小
播放效果:
高采样率重采 & 低采样率封装
现象:
- 播放声音变慢拖长
- 时间变长
- 文件大小变大
播放效果:
结合有关变声相关的文章:
从原理上来讲的话,其实变速就是在同样的采样率环境下,对采样数据进行拉伸或压缩。
从算法的角度上来说的话,可以认为是插值或抽值。
如果你让一个人讲话的速度变得更快怎么做,
很明显,就是在同样的采样率下,抽掉一些样本。
反之,降速则是插入一些样本。
最终决定变速效果的就是插入样本和抽离样本的权重计算。
那么此处的“变声”效果应该是在采样率改变的情况下形成的。
直接改变采样率会怎么样?
由于合成过程中有两个关键步骤:
// 1. 数据填充
context.createBuffer(
1, // numberOfChannels
totalLength(buffers),
sampleRate
);
// 2. 写入 wav 文件头
createBuffer会涉及到重采样,究竟是哪一步影响到了最终的结果呢?
目前得出的结论是,写入 WAV 文件头的采样率也会影响文件内容,即同样存在“重采样”。
我这里使用 sox 直接改写文件头中的采样率,文件的大小,频谱都发生了变化,将改完后的文件,重新再改写到原来的文件的采样率后,文件的频谱依旧发生了变化,因此推测系统做了重采样的操作。
./sox ../减少-11100.wav -r 44100 ../还原-1100+44100.wav目前如果想要合成的音频播放效果和原始的一致的话,只要将采样率设置成和系统采样率一样就可以了,也就是和 AudioContext.sampleRate 一致即可。