By Noxxxx from https://www.noxxxx.com/?post_type=post&p=1792
欢迎分享与聚合,尊重版权,可以联系授权
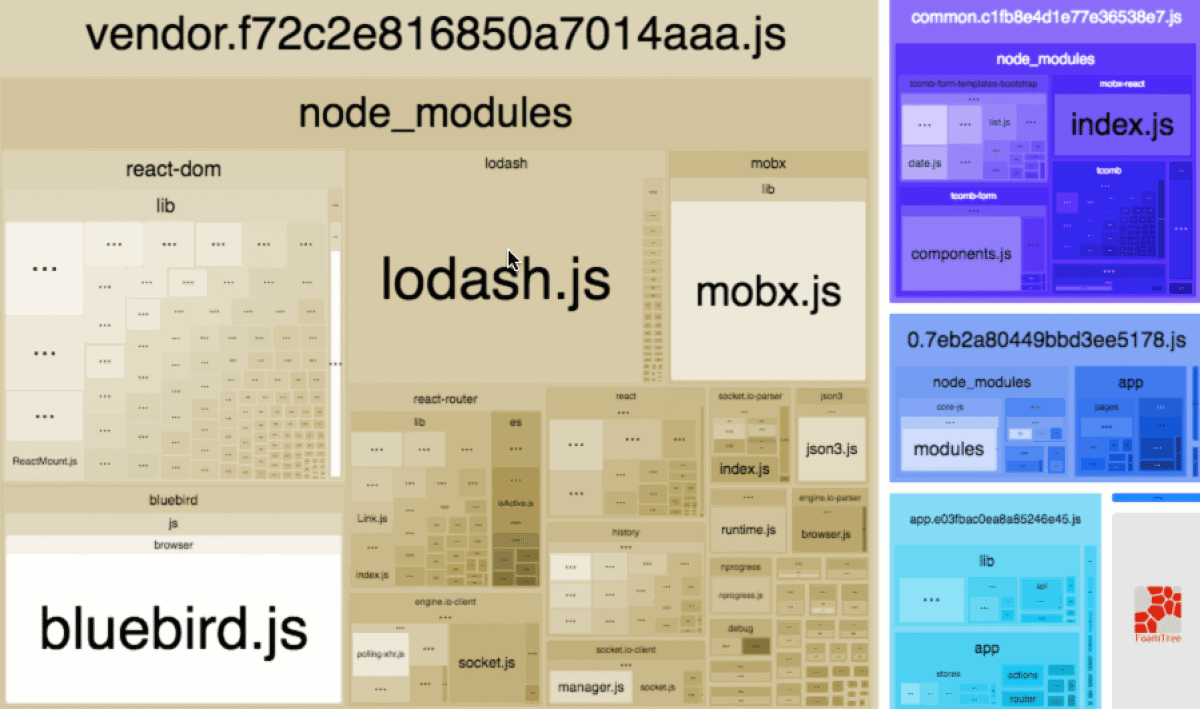
webpack-bundle-analyzer 是一个插件:通过分析构建产物,最终生成 矩形树图 方便开发者根据项目构建后的依赖关系以及实际的文件尺寸,来进行相应的性能优化。
为什么要研究这个插件?因为纵观当前的几类依赖分析的插件,包括 webpack 自身提供的一个工具 http://webpack.github.io/analyse/ 从可视化的角度来说,都没有 webpack-bundle-analyzer 提供的矩形树图来的直观:
以上几个工具都是只分析 stats.json 暴露的内容来生成图表。
而 webpack-bundle-analyzer 和他们之间的区别在于借助 acorn ,通过分析构建产物来得出模块依赖关系,核心实现上其实是脱离了 webpack 的能力,但由于是分析 webpack 的构建产物,因而要对打包出来的 js 内容的组装结构需要了解,随着 webpack 的不断升级,产物结构也会随之发生改变,因而需要不断的兼容,通过阅读源码以及作者的注释可以看到,webpack v5 的产物已经比较难以分析了
在看之前,需要先了解以下几个知识点:
- Webpack 提供的
stats属性中module,chunk,assets的含义。 - acorn:一个完全使用 Javascript 实现的,小型且快速的 Javascript 解析器 ,AST 抽象语法树相关知识。
核心的流程如下:
插件入口
首先是遵循 Webpack 插件的写法,在 done 函数里获取到 stats
class BundleAnalyzerPlugin {
apply(compiler) {
// 核心实现入口
const done = (stats, callback) => {/* ... */ }
// 兼容 webpack 新老版本的写法
if (compiler.hooks) {
compiler.hooks.done.tapAsync('webpack-bundle-analyzer', done);
} else {
compiler.plugin('done', done);
}
}
}webpack-bundle-analyzer 插件的数据源取自 stats.toJson() 这个方法,而生成图表数据的函数则是 getViewerData(),下面拆分了解这个函数的具体实现。
1. 确认资源的结构
const _ = require('lodash');
const FILENAME_QUERY_REGEXP = /\?.*$/u;
const FILENAME_EXTENSIONS = /\.(js|mjs)$/iu;
函数入参为 bundleStats
// Sometimes all the information is located in `children` array (e.g. problem in #10)
// assets 为空 && children 存在,这种情况下资源信息都在 children 属性当中
if (_.isEmpty(bundleStats.assets) && !_.isEmpty(bundleStats.children)) {
const { children } = bundleStats;
bundleStats = bundleStats.children[0];
// Sometimes if there are additional child chunks produced add them as child assets,
// leave the 1st one as that is considered the 'root' asset.
// 这种情况下 children 数组中的第一个元素当作根节点,children 数组中如果还有 assets,则 push 到 bundleStats.assets 中
for (let i = 1; i < children.length; i++) {
children[i].assets.forEach((asset) => {
asset.isChild = true;
bundleStats.assets.push(asset);
});
}
} else if (!_.isEmpty(bundleStats.children)) {
// Sometimes if there are additional child chunks produced add them as child assets
bundleStats.children.forEach((child) => {
child.assets.forEach((asset) => {
asset.isChild = true;
bundleStats.assets.push(asset);
});
});
}
// Picking only `*.js or *.mjs` assets from bundle that has non-empty `chunks` array
// 过滤出 *.js 和 *.mjs 并且 chunks 不为空的 assets
bundleStats.assets = bundleStats.assets.filter(asset => {
// Filter out non 'asset' type asset if type is provided (Webpack 5 add a type to indicate asset types)
if (asset.type && asset.type !== 'asset') {
return false;
}
// Removing query part from filename (yes, somebody uses it for some reason and Webpack supports it)
// See #22
asset.name = asset.name.replace(FILENAME_QUERY_REGEXP, '');
return FILENAME_EXTENSIONS.test(asset.name) && !_.isEmpty(asset.chunks);
});拿一个项目来举例,图片里的内容是取自 stats.json() ,上面这段代码最后提取的产物是图中标注的三个对象:

2. 使用 Acorn AST 分析
接着开始遍历一个数组,数组中的内容是上面的三个对象。
首先判断 compiler.outputPath 是否存在?存在就用 acorn 库解析 JS 文件,调用 acorn-walk 的 recursive 方法递归处理解析后的 AST 树🌲。
AST 相关的源码:
const fs = require('fs');
const _ = require('lodash');
const acorn = require('acorn');
const walk = require('acorn-walk');
// 传入路径
function parseBundle(bundlePath) {
const content = fs.readFileSync(bundlePath, 'utf8');
// acorn 解析 js 文件内容
const ast = acorn.parse(content, {
sourceType: 'script',
// I believe in a bright future of ECMAScript!
// Actually, it's set to `2050` to support the latest ECMAScript version that currently exists.
// Seems like `acorn` supports such weird option value.
ecmaVersion: 2050
});
const walkState = {
locations: null,
expressionStatementDepth: 0
};
// 递归执行
walk.recursive(
ast,
walkState,
{
// 表达式语句节点
ExpressionStatement(node, state, c) {
if (state.locations) return;
state.expressionStatementDepth++; // expressionStatement 深度 +1
if (
// Webpack 5 stores modules in the the top-level IIFE
state.expressionStatementDepth === 1 &&
ast.body.includes(node) &&
isIIFE(node)
) {
const fn = getIIFECallExpression(node);
if (
// It should not contain neither arguments
fn.arguments.length === 0 &&
// ...nor parameters
fn.callee.params.length === 0
) {
// Modules are stored in the very first variable declaration as hash
const firstVariableDeclaration = fn.callee.body.body.find(node => node.type === 'VariableDeclaration');
if (firstVariableDeclaration) {
for (const declaration of firstVariableDeclaration.declarations) {
if (declaration.init) {
state.locations = getModulesLocations(declaration.init);
if (state.locations) {
break;
}
}
}
}
}
}
if (!state.locations) {
c(node.expression, state);
}
state.expressionStatementDepth--;
},
// 赋值表达式节点
AssignmentExpression(node, state) {
if (state.locations) return;
// Modules are stored in exports.modules:
// exports.modules = {};
const { left, right } = node;
if (
left &&
left.object && left.object.name === 'exports' &&
left.property && left.property.name === 'modules' &&
isModulesHash(right)
) {
state.locations = getModulesLocations(right);
}
},
// 函数调用表达式
CallExpression(node, state, c) {
if (state.locations) return;
const args = node.arguments;
// Main chunk with webpack loader.
// Modules are stored in first argument:
// (function (...) {...})(<modules>)
if (
node.callee.type === 'FunctionExpression' &&
!node.callee.id &&
args.length === 1 &&
isSimpleModulesList(args[0])
) {
state.locations = getModulesLocations(args[0]);
return;
}
// Async Webpack < v4 chunk without webpack loader.
// webpackJsonp([<chunks>], <modules>, ...)
// As function name may be changed with `output.jsonpFunction` option we can't rely on it's default name.
if (
node.callee.type === 'Identifier' &&
mayBeAsyncChunkArguments(args) &&
isModulesList(args[1])
) {
state.locations = getModulesLocations(args[1]);
return;
}
// Async Webpack v4 chunk without webpack loader.
// (window.webpackJsonp=window.webpackJsonp||[]).push([[<chunks>], <modules>, ...]);
// As function name may be changed with `output.jsonpFunction` option we can't rely on it's default name.
if (isAsyncChunkPushExpression(node)) {
state.locations = getModulesLocations(args[0].elements[1]);
return;
}
// Webpack v4 WebWorkerChunkTemplatePlugin
// globalObject.chunkCallbackName([<chunks>],<modules>, ...);
// Both globalObject and chunkCallbackName can be changed through the config, so we can't check them.
if (isAsyncWebWorkerChunkExpression(node)) {
state.locations = getModulesLocations(args[1]);
return;
}
// Walking into arguments because some of plugins (e.g. `DedupePlugin`) or some Webpack
// features (e.g. `umd` library output) can wrap modules list into additional IIFE.
args.forEach(arg => c(arg, state));
}
}
);
let modules;
if (walkState.locations) {
modules = _.mapValues(walkState.locations,
loc => content.slice(loc.start, loc.end)
);
} else {
modules = {};
}
return {
modules, // 获取 modules
src: content, // 内容
runtimeSrc: getBundleRuntime(content, walkState.locations) // 没有包含 modules 的 bundle 产物代码
};
}
/**
* Returns bundle source except modules
*/
function getBundleRuntime(content, modulesLocations) {
const sortedLocations = Object.values(modulesLocations || {})
.sort((a, b) => a.start - b.start);
let result = '';
let lastIndex = 0;
for (const { start, end } of sortedLocations) {
result += content.slice(lastIndex, start);
lastIndex = end;
}
return result + content.slice(lastIndex, content.length);
}
function isIIFE(node) {
return (
node.type === 'ExpressionStatement' &&
(
node.expression.type === 'CallExpression' ||
(node.expression.type === 'UnaryExpression' && node.expression.argument.type === 'CallExpression')
)
);
}
function getIIFECallExpression(node) {
if (node.expression.type === 'UnaryExpression') {
return node.expression.argument;
} else {
return node.expression;
}
}
function isModulesList(node) {
return (
isSimpleModulesList(node) ||
// Modules are contained in expression `Array([minimum ID]).concat([<module>, <module>, ...])`
isOptimizedModulesArray(node)
);
}
function isSimpleModulesList(node) {
return (
// Modules are contained in hash. Keys are module ids.
isModulesHash(node) ||
// Modules are contained in array. Indexes are module ids.
isModulesArray(node)
);
}
function isModulesHash(node) {
return (
node.type === 'ObjectExpression' &&
node.properties
.map(node => node.value)
.every(isModuleWrapper)
);
}
function isModulesArray(node) {
return (
node.type === 'ArrayExpression' &&
node.elements.every(elem =>
// Some of array items may be skipped because there is no module with such id
!elem ||
isModuleWrapper(elem)
)
);
}
function isOptimizedModulesArray(node) {
// Checking whether modules are contained in `Array(<minimum ID>).concat(...modules)` array:
// https://github.com/webpack/webpack/blob/v1.14.0/lib/Template.js#L91
// The `<minimum ID>` + array indexes are module ids
return (
node.type === 'CallExpression' &&
node.callee.type === 'MemberExpression' &&
// Make sure the object called is `Array(<some number>)`
node.callee.object.type === 'CallExpression' &&
node.callee.object.callee.type === 'Identifier' &&
node.callee.object.callee.name === 'Array' &&
node.callee.object.arguments.length === 1 &&
isNumericId(node.callee.object.arguments[0]) &&
// Make sure the property X called for `Array(<some number>).X` is `concat`
node.callee.property.type === 'Identifier' &&
node.callee.property.name === 'concat' &&
// Make sure exactly one array is passed in to `concat`
node.arguments.length === 1 &&
isModulesArray(node.arguments[0])
);
}
function isModuleWrapper(node) {
return (
// It's an anonymous function expression that wraps module
((node.type === 'FunctionExpression' || node.type === 'ArrowFunctionExpression') && !node.id) ||
// If `DedupePlugin` is used it can be an ID of duplicated module...
isModuleId(node) ||
// or an array of shape [<module_id>, ...args]
(node.type === 'ArrayExpression' && node.elements.length > 1 && isModuleId(node.elements[0]))
);
}
// 判断是否为 module id
function isModuleId(node) {
return (node.type === 'Literal' && (isNumericId(node) || typeof node.value === 'string'));
}
// 判断是否为数字类型 id
function isNumericId(node) {
return (node.type === 'Literal' && Number.isInteger(node.value) && node.value >= 0);
}
function isChunkIds(node) {
// Array of numeric or string ids. Chunk IDs are strings when NamedChunksPlugin is used
return (
node.type === 'ArrayExpression' &&
node.elements.every(isModuleId)
);
}
function isAsyncChunkPushExpression(node) {
const {
callee,
arguments: args
} = node;
return (
callee.type === 'MemberExpression' &&
callee.property.name === 'push' &&
callee.object.type === 'AssignmentExpression' &&
args.length === 1 &&
args[0].type === 'ArrayExpression' &&
mayBeAsyncChunkArguments(args[0].elements) &&
isModulesList(args[0].elements[1])
);
}
function mayBeAsyncChunkArguments(args) {
return (
args.length >= 2 &&
isChunkIds(args[0])
);
}
function isAsyncWebWorkerChunkExpression(node) {
const { callee, type, arguments: args } = node;
return (
type === 'CallExpression' &&
callee.type === 'MemberExpression' &&
args.length === 2 &&
isChunkIds(args[0]) &&
isModulesList(args[1])
);
}
// 获取模块位置
function getModulesLocations(node) {
if (node.type === 'ObjectExpression') {
// Modules hash
const modulesNodes = node.properties;
return modulesNodes.reduce((result, moduleNode) => {
const moduleId = moduleNode.key.name || moduleNode.key.value;
result[moduleId] = getModuleLocation(moduleNode.value);
return result;
}, {});
}
const isOptimizedArray = (node.type === 'CallExpression');
if (node.type === 'ArrayExpression' || isOptimizedArray) {
// Modules array or optimized array
const minId = isOptimizedArray ?
// Get the [minId] value from the Array() call first argument literal value
node.callee.object.arguments[0].value :
// `0` for simple array
0;
const modulesNodes = isOptimizedArray ?
// The modules reside in the `concat()` function call arguments
node.arguments[0].elements :
node.elements;
return modulesNodes.reduce((result, moduleNode, i) => {
if (moduleNode) {
result[i + minId] = getModuleLocation(moduleNode);
}
return result;
}, {});
}
return {};
}
function getModuleLocation(node) {
return {
start: node.start,
end: node.end
};
}
module.exports = parseBundle;分别使用到了下面三个函数分析构建后的 js 文件。
ExpressionStatement 表达式语句节点
AssignmentExpression 赋值表达式节点
CallExpression 函数调用表达式
看不明白?先试着看下面的:
解析前:
module.exports = test; // test 是一个函数解析后:
{
"type": "Program",
"start": 0,
"end": 201,
"body": [
{
"type": "ExpressionStatement",
"start": 179,
"end": 201,
"expression": {
"type": "AssignmentExpression",
"start": 179,
"end": 200,
"operator": "=",
"left": {
"type": "MemberExpression",
"start": 179,
"end": 193,
"object": {
"type": "Identifier",
"start": 179,
"end": 185,
"name": "module"
},
"property": {
"type": "Identifier",
"start": 186,
"end": 193,
"name": "exports"
},
"computed": false,
"optional": false
},
"right": {
"type": "Identifier",
"start": 196,
"end": 200,
"name": "test"
}
}
}
],
"sourceType": "module"
}解析前:
(
function(e){}
)(
0, (function () {})()
)解析后:
{
"type": "Program",
"start": 0,
"end": 46,
"body": [
{
"type": "ExpressionStatement",
"start": 0,
"end": 46,
"expression": {
"type": "CallExpression",
"start": 0,
"end": 46,
"callee": {
"type": "FunctionExpression",
"start": 4,
"end": 17,
"id": null,
"expression": false,
"generator": false,
"async": false,
"params": [
{
"type": "Identifier",
"start": 13,
"end": 14,
"name": "e"
}
],
"body": {
"type": "BlockStatement",
"start": 15,
"end": 17,
"body": []
}
},
"arguments": [
{
"type": "Literal",
"start": 23,
"end": 24,
"value": 0,
"raw": "0"
},
{
"type": "CallExpression",
"start": 26,
"end": 44,
"callee": {
"type": "FunctionExpression",
"start": 27,
"end": 41,
"id": null,
"expression": false,
"generator": false,
"async": false,
"params": [],
"body": {
"type": "BlockStatement",
"start": 39,
"end": 41,
"body": []
}
},
"arguments": [],
"optional": false
}
],
"optional": false
}
}
],
"sourceType": "module"
}上面举例了两种写法以及对应的 AST 生成结果,对照 webpack-bundle-analyzer 这部分的源码,按照个人理解,作者\枚举了 webpack 输出产物的几种结构,通过编写对应的解析方法来实现对依赖的获取。
因而parseBundle 函数的作用是为了分析出依赖的代码块,这个代码块就是最终构建产物,也就是某个 JS 文件中的一段代码,在构建过程中 JS 文件里的代码都是字符串,因而就是对字符串的切割。通过 AST 分析得到的结构中有 start,end 两个属性,这两个属性代表着一个代码块在源文件中的位置,所以使用 slice(start, end) 也就可以拿到对应 模块 的实际代码。
通过分析,最终这一步是获得了:
{
modules, // 获取 modules
src: content, // 内容
runtimeSrc: getBundleRuntime(content, walkState.locations) // 没有包含 modules 的 bundle 产物代码
}上述三个属性。
看一下输出结果:bundleInfo 一共输出了三次,符合之前的过滤结果。那像这些 0a3c 已经被编号过的 module 如何跟实际的 node_modules 内的文件相关联呢?继续往下看👇

3. 遍历 assets 属性,开始组装对象
// bundleStats 就是 stats.json() 的内容
const assets = bundleStats.assets.reduce((result, statAsset) => {
// If asset is a childAsset, then calculate appropriate bundle modules by looking through stats.children
const assetBundles = statAsset.isChild ? getChildAssetBundles(bundleStats, statAsset.name) : bundleStats;
const modules = assetBundles ? getBundleModules(assetBundles) : []; // 所有的 modules 合集
const asset = result[statAsset.name] = _.pick(statAsset, 'size');
const assetSources = bundlesSources && _.has(bundlesSources, statAsset.name) ?
bundlesSources[statAsset.name] : null;
if (assetSources) {
asset.parsedSize = Buffer.byteLength(assetSources.src);
asset.gzipSize = gzipSize.sync(assetSources.src);
}
// Picking modules from current bundle script
// 根据 chunks(数组) 字段来进行过滤 statAssets 和 statModule 都含有 chunks 进行比对
const assetModules = modules.filter(statModule => assetHasModule(statAsset, statModule));
// Adding parsed sources
if (parsedModules) {
const unparsedEntryModules = [];
for (const statModule of assetModules) {
if (parsedModules[statModule.id]) {
statModule.parsedSrc = parsedModules[statModule.id]; // 提取先前 ast 解析的 module
} else if (isEntryModule(statModule)) { // 根据 depth 为 0判断是否为入口 module
unparsedEntryModules.push(statModule);
}
}
// Webpack 5 changed bundle format and now entry modules are concatenated and located at the end of it.
// Because of this they basically become a concatenated module, for which we can't even precisely determine its
// parsed source as it's located in the same scope as all Webpack runtime helpers.
if (unparsedEntryModules.length && assetSources) {
if (unparsedEntryModules.length === 1) {
// So if there is only one entry we consider its parsed source to be all the bundle code excluding code
// from parsed modules.
unparsedEntryModules[0].parsedSrc = assetSources.runtimeSrc;
} else {
// If there are multiple entry points we move all of them under synthetic concatenated module.
_.pullAll(assetModules, unparsedEntryModules);
assetModules.unshift({
identifier: './entry modules',
name: './entry modules',
modules: unparsedEntryModules,
size: unparsedEntryModules.reduce((totalSize, module) => totalSize + module.size, 0),
parsedSrc: assetSources.runtimeSrc
});
}
}
}
asset.modules = assetModules;
asset.tree = createModulesTree(asset.modules);
return result;
}, {});
function getChildAssetBundles(bundleStats, assetName) {
return (bundleStats.children || []).find((c) =>
_(c.assetsByChunkName)
.values()
.flatten()
.includes(assetName)
);
}
function getBundleModules(bundleStats) {
return _(bundleStats.chunks)
.map('modules') // chunks 下的 modules 数组和 bundleStats.modules 合并
.concat(bundleStats.modules)
.compact()
.flatten()
.uniqBy('id')
// Filtering out Webpack's runtime modules as they don't have ids and can't be parsed (introduced in Webpack 5)
.reject(isRuntimeModule)
.value();
}
// 判断资源是否包含 module
function assetHasModule(statAsset, statModule) {
// Checking if this module is the part of asset chunks
return (statModule.chunks || []).some(moduleChunk =>
statAsset.chunks.includes(moduleChunk)
);
}
function isEntryModule(statModule) {
return statModule.depth === 0;
}
function isRuntimeModule(statModule) {
return statModule.moduleType === 'runtime';
}
function createModulesTree(modules) {
const root = new Folder('.');
modules.forEach(module => root.addModule(module));
root.mergeNestedFolders();
return root;
}3.1 createModulesTree 实现
function createModulesTree(modules) {
const root = new Folder('.');
modules.forEach(module => root.addModule(module));
root.mergeNestedFolders();
return root;
}该函数遍历的是每一个 module,如下图所示,此时的 module 的结构:

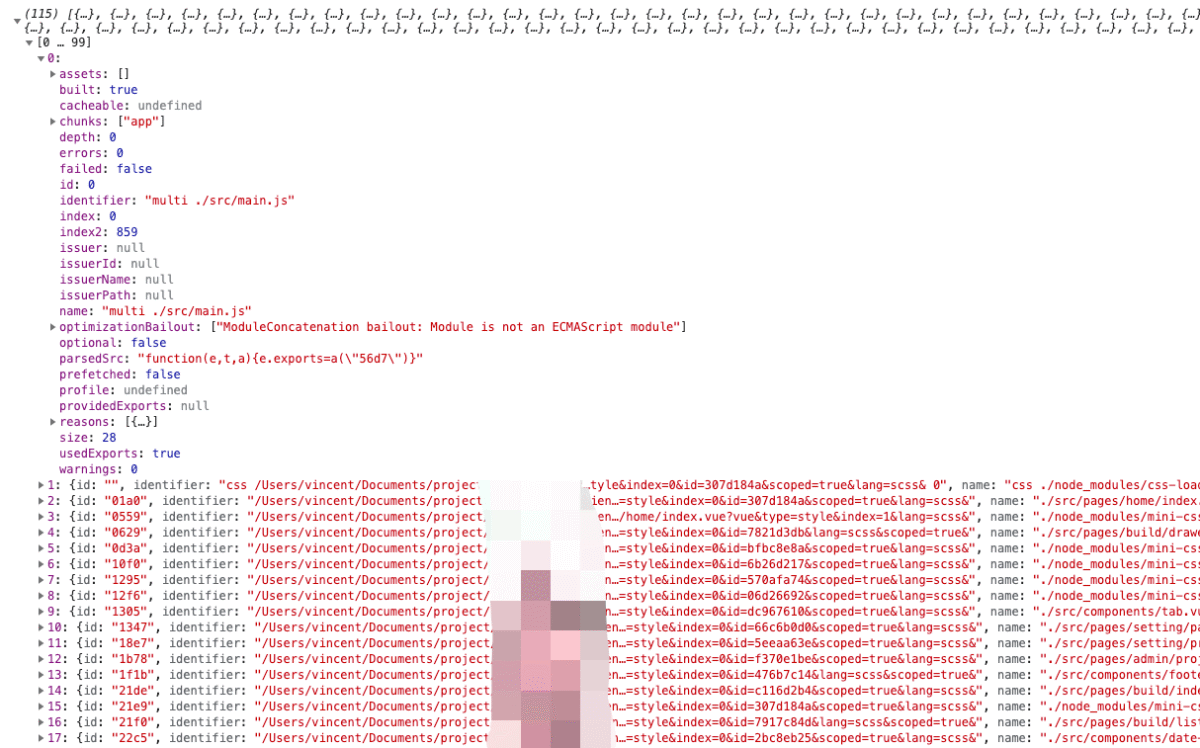
观察 name 字段,一个是带 multi 一个是不带的。
看一下 addModule 运行的结果:
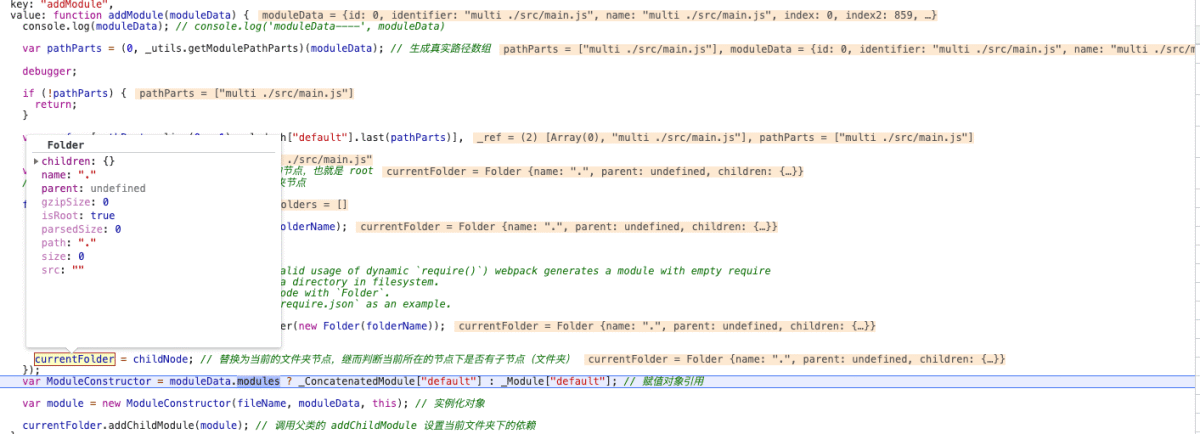
getModulePathParts() 通过对 name 字段的拆分,构造文件夹来对应文件的归属。
addModule(moduleData) {
const pathParts = getModulePathParts(moduleData); // 生成真实路径数组
if (!pathParts) {
return;
}
const [folders, fileName] = [pathParts.slice(0, -1), _.last(pathParts)]; // 如果 name 是带有 multi ,则 folders 为空, filename 则为 multi ./src/main.js
let currentFolder = this; // 刚开始为调用者的节点,也就是 root
// 遍历文件夹路径数组,目的是为了创建所有的子文件夹节点
folders.forEach(folderName => {
// 或者这个文件夹下是否已经有子文件夹
let childNode = currentFolder.getChild(folderName);
if (
// Folder is not created yet
// 文件夹没有被创建过,则创建
!childNode ||
// In some situations (invalid usage of dynamic `require()`) webpack generates a module with empty require
// context, but it's moduleId points to a directory in filesystem.
// In this case we replace this `File` node with `Folder`.
// See `test/stats/with-invalid-dynamic-require.json` as an example.
!(childNode instanceof Folder)
) {
childNode = currentFolder.addChildFolder(new Folder(folderName));
}
currentFolder = childNode; // 替换为当前的文件夹节点,继而判断当前所在的节点下是否有子节点(文件夹)
});
const ModuleConstructor = moduleData.modules ? ConcatenatedModule : Module; // 赋值对象引用
const module = new ModuleConstructor(fileName, moduleData, this); // 实例化对象
currentFolder.addChildModule(module); // 调用父类的 addChildModule 设置当前文件夹下的依赖这块的代码核心是递归,构造每一个目录和对应的文件:录了个视频,看起来更直观,通过 debug 的方式。来看最终生成的产物:
参考资料:
https://github.com/estree
https://github.com/acornjs/acorn/tree/master/acorn-walk
https://astexplorer.net/
https://webpack.js.org/concepts/under-the-hood/#the-main-parts